前言
你有过使用搜索引擎搜索问题却怎么也找不到有效信息的时候吗?
拥有大模型之前我们使用搜索引擎去搜索问题,然而由于网页内容质量参差不齐,你有可能看了五个网页也找不到自己的答案 |
拥有大模型之后直接将输入搜索引擎的问题输入大模型,比如“如何安装Python”,由于大模型有非常庞大且高质量的知识,因此它会输出正确答案,而且会包含不同系统的Python安装方法,比我们直接使用搜索引擎寻找答案方便多了。 |
|---|
大模型的影响力已经逐渐散播到我们生活的方方面面。从2022年底ChatGPT的一鸣惊人,再到持续进行的"百模大战","大模型"已经逐渐成为了技术和公众领域的热点。
大模型是人工智能领域的一个重要里程碑,它推动了人工智能技术的发展,并为人类的未来带来新的可能性。有人曾经类比,大模型的发明相当于人类文明的哪个节点?一个浪漫的答案可能是:人类学会使用火的时刻。

大模型的发明相当于人类学会使用火的时刻(图片由AI大模型生成)
学习目标
学完本课程后,您将能够:
- 掌握大模型的特点、重要概念以及工作方式
- 了解阿里云大模型的基本概况和产品矩阵
- 了解大模型,尤其是大语言模型的应用场景和示例
1 关于“大模型”,你应该知道的
1.1 从人工智能到大模型的演变
大模型是人工智能发展历程中的重要里程碑。在对大模型进行深入了解之前,我们有必要回望一些人工智能的重要概念,这不仅可以让我们了解大模型是如何被塑造的,更能帮助我们全面地理解大模型的原理和潜能。
人工智能(AI)是一门使机器模拟人类智能过程的学科,其中具体包括学习、推理、自我修正、感知和处理语言等功能。人工智能涉及计算机科学、数学、心理学等众多领域的知识,通过创建能够实现智能行为的算法或软件系统,来表现出与人类的智能行为相似的特性。
人工智能按照技术实现的不同可被划分为多个子领域,各个子领域之间往往相互关联和影响。

[灯泡]在了解了人工智能的不同领域之后,下面我们需要针对这些领域补齐一些重要概念,这对后续的大模型学习至关重要。
1.2 大模型,它来了!
2021年,斯坦福大学的研究员团队发表了一篇论文,提出了Foundational Models(基础模型,即大模型)的概念。简单来说,它是一类具有大量参数(通常在十亿以上),能在极为广泛的数据上进行训练,并适用于多种任务和应用的预训练深度学习模型。
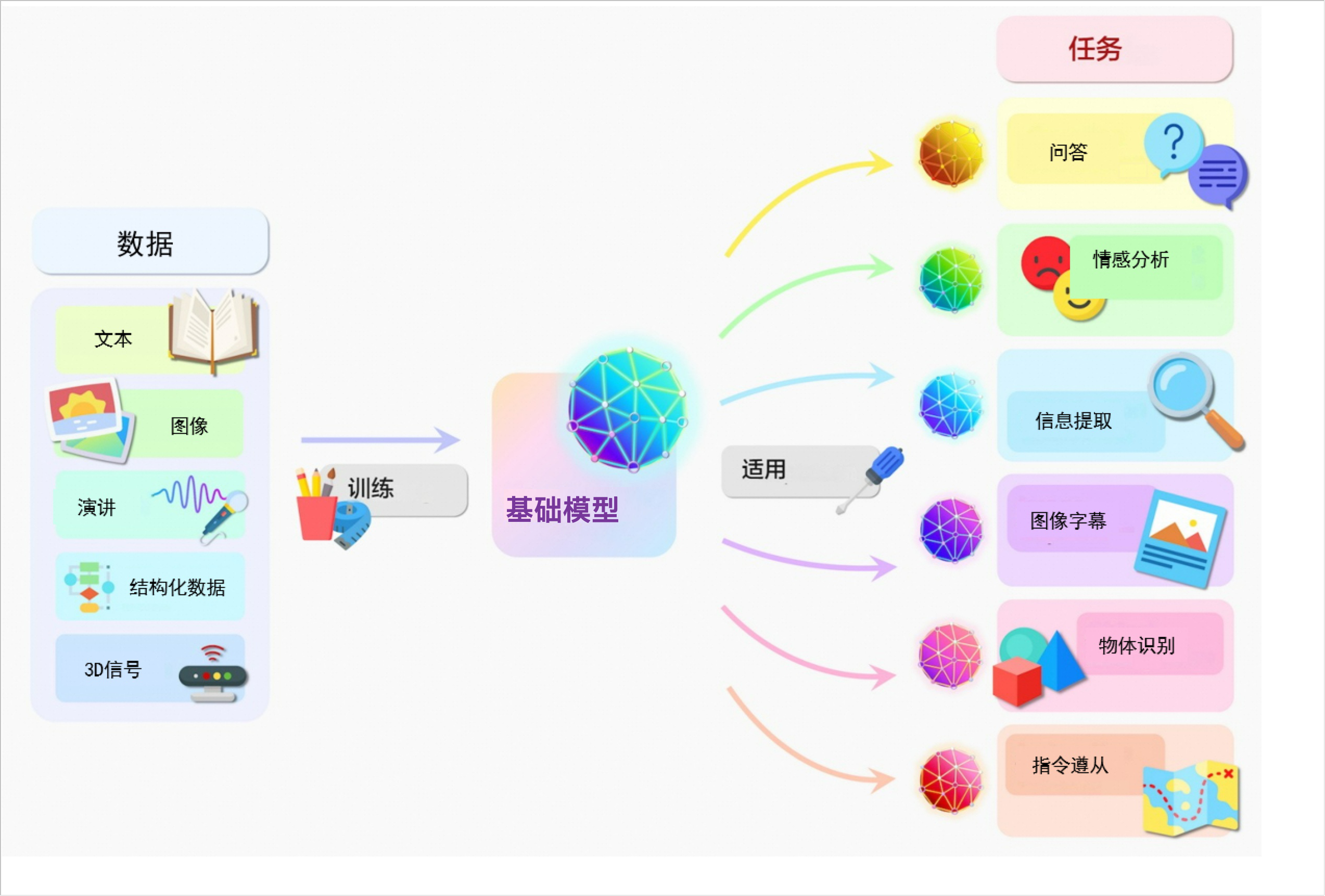
大模型通过广泛数据集的训练后,可以适用于多种多样的需求
2022年11月,OpenAI公司发布了ChatGPT——一种先进的人工智能语言模型,专为对话交互而设计,具有强大的自然语言理解和生成能力,可以完成撰写论文、邮件、脚本、文案、翻译、代码等任务。ChatGPT的发布标志着AI大模型在语言理解与生成能力上的重大突破,对全球AI产业产生了深远影响,开启了人工智能大模型应用的新篇章。

2023年3月,国内厂商纷纷发布各自研发的大语言模型产品。百度发布文心一言、阿里巴巴集团通义千问开始企业内测、商汤科技带来了商量SenseChat、360启动360智脑企业内测、华为盘古大模型、科大讯飞1+N认知大模型、昆仑万维的天工大模型、以及京东言犀、腾讯混元......百模大战一触即发。

2023年8月,阿里巴巴集团发布了通义千问系列开源大模型,并相继推出了7B(约70亿参数)、72B(约720亿参数)等不同参数规模的大语言模型版本。目前,通义千问系列大语言模型已升级至Qwen3版本,具备自然语言理解、文本生成、视觉理解、音频理解、工具使用、角色扮演、作为AI Agent进行互动等多种能力。
无论是语言模型还是多模态模型,均在大规模多语言和多模态数据上进行预训练,并通过高质量数据进行后期微调以贴近人类偏好。
1.3 能力强,很好用!
大模型的使用方法非常简单,我们可以通过阿里云百炼直接向大模型提出需求,就能获得生动翔实的答复。
例如:请从技术领先、稳定可靠、安全合规这三点来介绍我们为什么要使用阿里云(查询专业知识可以启用知识库检索功能,提升知识问答准确率)
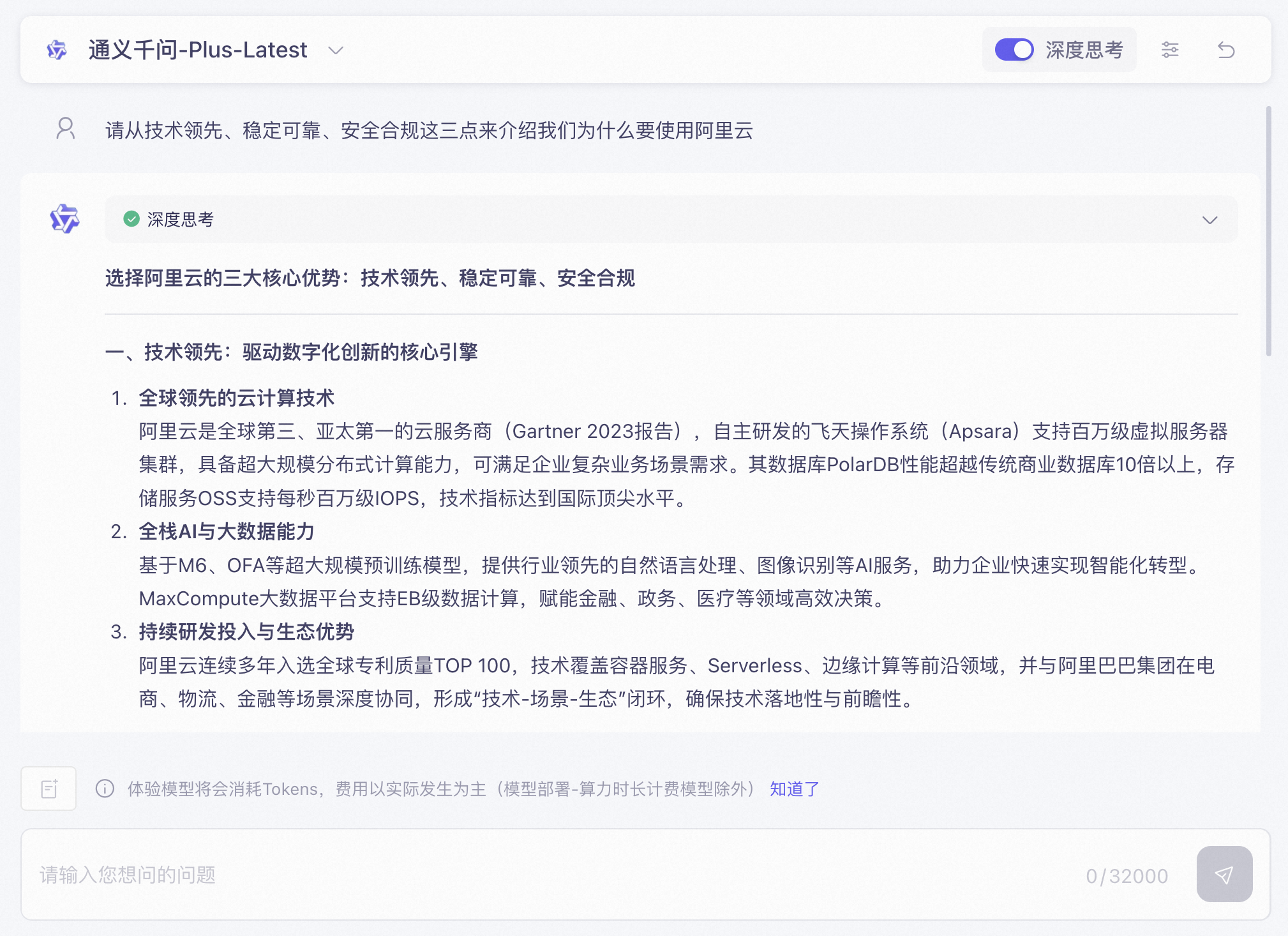
您可以通过以下步骤开启大模型体验之旅:进入“百炼->文本模型->文本对话”体验区后,点击“更多模型”,选择“Qwen-Plus-Latest”大模型,随后点击“立即体验”
1.4 大模型的训练
你可能会好奇大模型是如何通过训练得到的,我们可以看下边这张图:

大模型的训练整体上分为三个阶段:预训练、SFT(监督微调)以及RLHF(基于人类反馈的强化学习)。
1.5 大模型的特点
基础模型(大模型)主要有以下四个特点:
| [优先级: 1]规模和参数量大 大模型通过其庞大的规模(拥有从数亿到数千亿级别的参数数量)来捕获复杂的数据模式,使得它们能够理解和生成极其丰富的信息。 |
[优先级: 2]适应性和灵活性强 模型具有很强的适应性和灵活性,能够通过微调(fine-tune)或少样本学习高效地迁移到各种下游任务,有很强的跨域能力。 |
|---|---|
| [优先级: 3]广泛数据集的预训练 大模型使用大量多样化的数据进行预训练,以学习广泛的知识表示,能够掌握语言、图像等数据的通用特征。 |
[优先级: 4]计算资源需求大 巨大的模型规模带来了高昂的计算和资源需求,包括但不限于数据存储、训练时间、能量消耗和硬件设施。 |
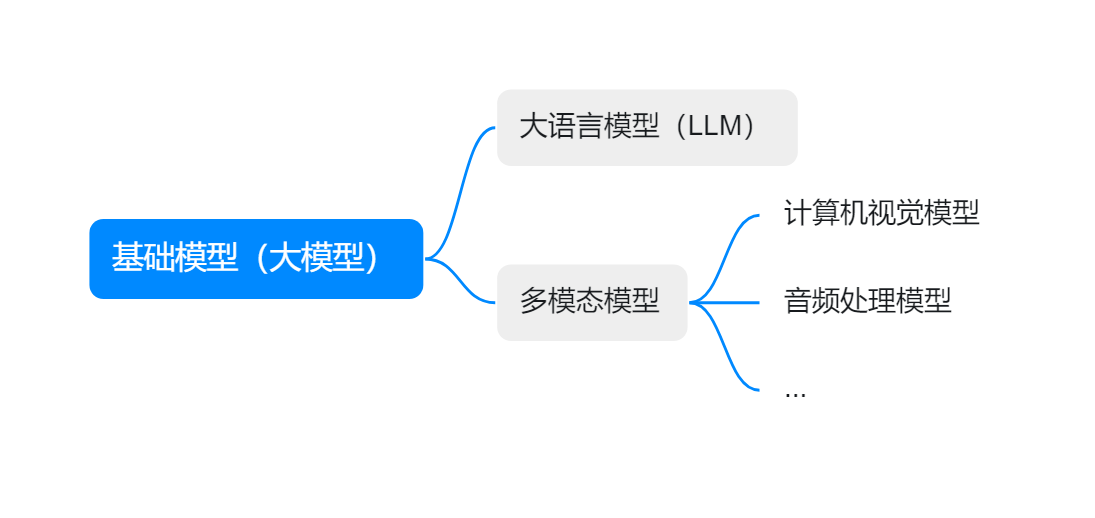
1.6 大模型的分类
按照应用场景,大模型可以大致分为:
2 大模型是如何工作的
用户在可以使用自然语言与大模型交流,用户的文本就是“提示词”。提示词越清晰,模型的回答就越符合预期。
大模型处理提示词的工作流程可以分为两部分,第一部分是分词化与词表映射,第二部分为生成文本。
2.1 分词化(Tokenization)与词表映射
分词化(Tokenization)是自然语言处理(NLP)中的重要概念,它是将段落和句子分割成更小的分词(token)的过程。举一个实际的例子,以下是一个英文句子:
I want to study ACA.
为了让机器理解这个句子,对字符串执行分词化,将其分解为独立的单元。使用分词化,我们会得到这样的结果:
['I' ,'want' ,'to' ,'study' ,'ACA' ,'.']
将一个句子分解成更小的、独立的部分可以帮助计算机理解句子的各个部分,以及它们在上下文中的作用,这对于进行大量上下文的分析尤其重要。分词化有不同的粒度分类:
- 词粒度(Word-Level Tokenization)分词化,如上文中例子所示,适用于大多数西方语言,如英语。
- 字符粒度(Character-Level)分词化是中文最直接的分词方法,它是以单个汉字为单位进行分词化。
- 子词粒度(Subword-Level)分词化,它将单词分解成更小的单位,比如词根、词缀等。这种方法对于处理新词(比如专有名词、网络用语等)特别有效,因为即使是新词,它的组成部分(子词)很可能已经存在于词表中了。
每一个token都会通过预先设置好的词表,映射为一个 token id,这是token 的“身份证”,一句话最终会被表示为一个元素为token id的列表,供计算机进行下一步处理。

这两句话包含了16个tokens
2.2 大语言模型生成文本的过程
大语言模型的工作概括来说是根据给定的文本预测下一个token。对我们来说,看似像在对大模型提问,但实际上是给了大模型一串提示文本,让它可以对后续的文本进行推理。
大模型的推理过程不是一步到位的,当大模型进行推理时,它会基于现有的token,根据概率最大原则预测出下一个最有可能的token,然后将该预测的token加入到输入序列中,并将更新后的输入序列继续输入大模型预测下一个token,这个过程叫做自回归。直到输出特殊token(如<EOS>,end of sentence,专门用来控制推理何时结束)或输出长度达到阈值,
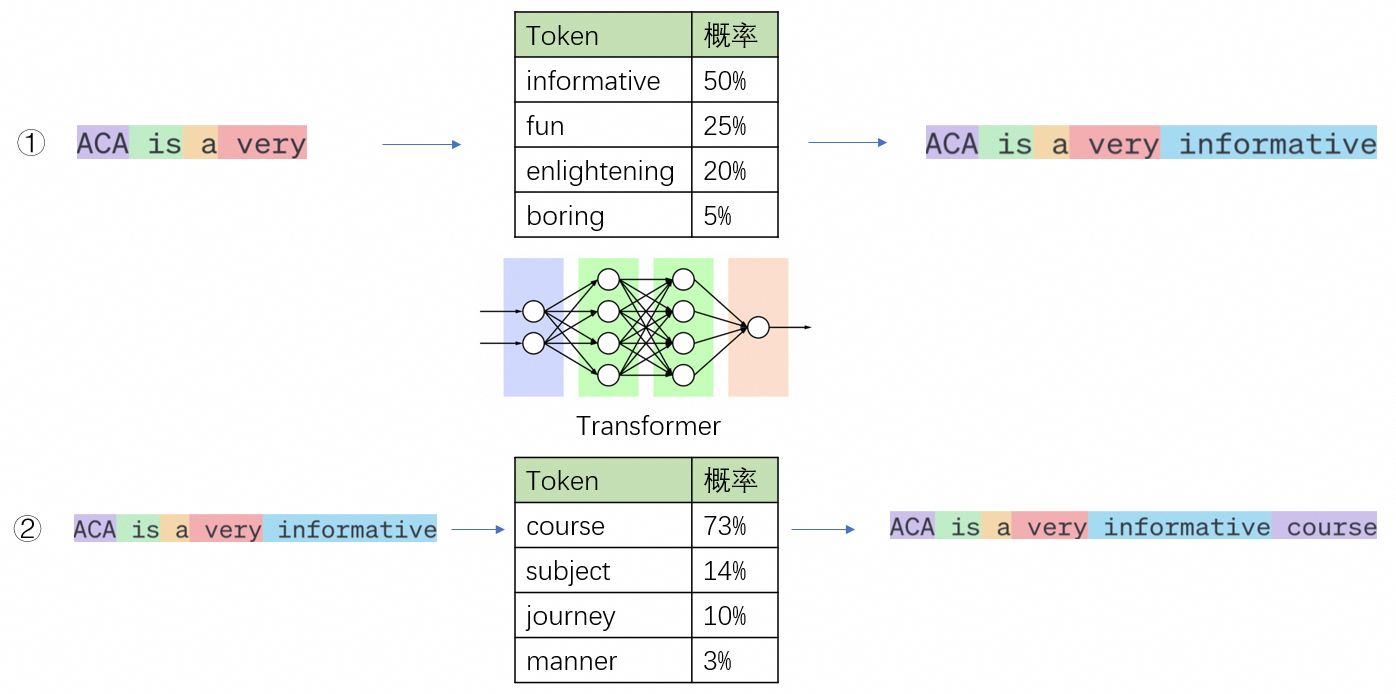
如下面的例子:
用户提问:阿里云成立于什么时间?
模型输出:

3. 大模型的应用
3.1 阿里云的大模型探索
阿里巴巴通义系列产品,是涵盖多领域、覆盖200多个服务场景的先进人工智能大模型体系。该系列产品矩阵涵盖金融、法律、科研、医疗、教育等专业领域,以及日常生活中的诸多需求,真正体现了“通情,达义”的设计理念,致力于成为人们工作、学习、生活中的全能助手。 此外,阿里云秉持开放姿态,将其核心模型开源开放给全球开发者,以此促进AI技术的共享与进步。
通义千问是阿里云自主研发的超大规模的语言模型,在复杂指令理解、文学创作、通用数学、代码理解生成、知识记忆等能力上均达到领先水平。它支持多种语言,还能处理多种分辨率和规格的图像,实现多语言多模态理解。
通义万相是阿里云自主研发多模态图像和视频生成模型,可提供AI艺术创作,可支持文生图、图生图、图生视频、虚拟模特、个人写真等多场景的图片和视频创作能力。
通义千问和通义万相是阿里巴巴通义系列产品中的基础模型。基于它们的能力,结合实际应用场景,阿里云构建了多个应用模型。我们稍后将展开介绍。
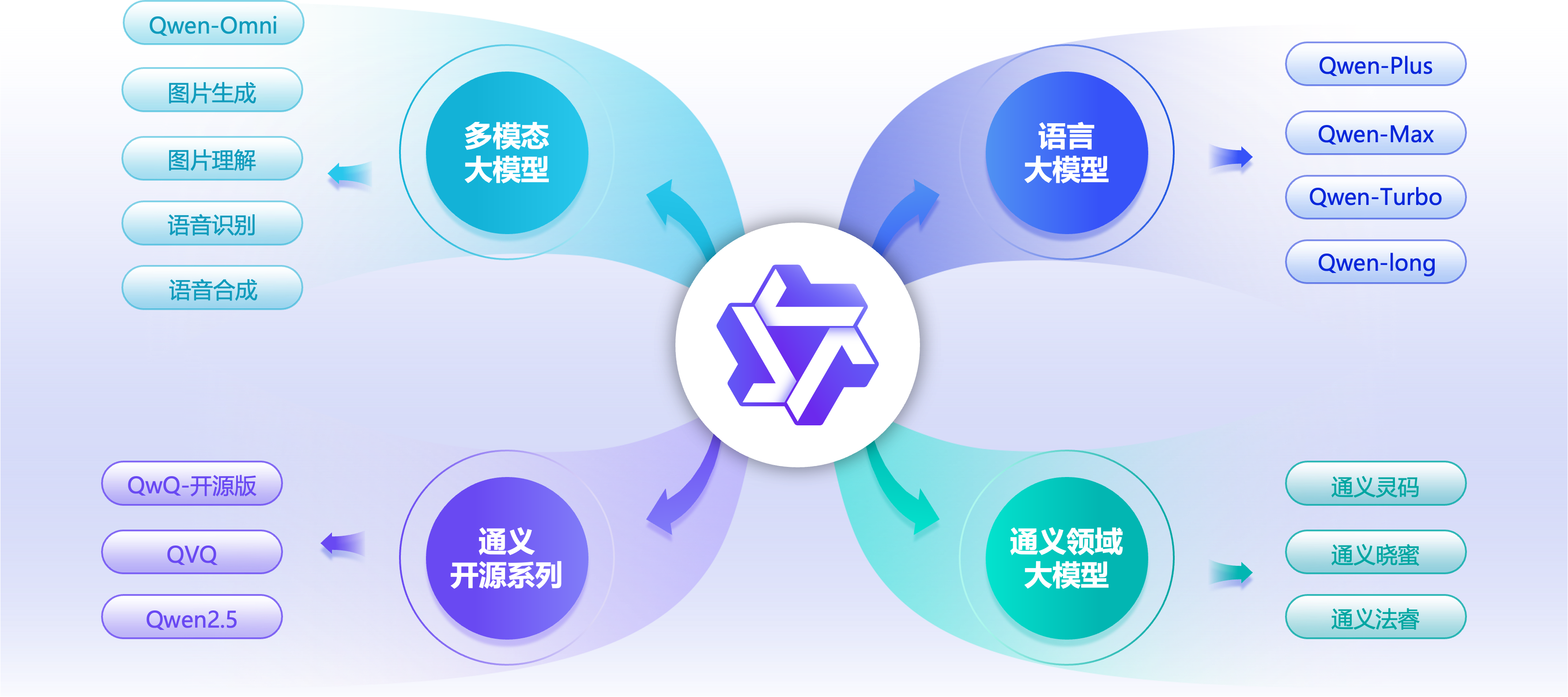
通义大模型产品家族
百炼大模型服务平台是基于阿里云通义大模型构建的,面向企业开发者、个人开发者及ISV合作伙伴提供通义系列大模型、三方大模型等调用、模型训练开发及大模型应用构建的服务平台。提供完整的模型训练工具和全链路开发套件,预置丰富的应用插件,提供便捷的集成方式,结合企业专属数据和 API,帮企业高效完成大模型应用构建。
在后续课程中,我们将基于百炼平台进行实操部分的练习。

百炼大模型服务平台
大模型的应用场景非常广泛,这里通过介绍通义系列产品提供几个常见的场景。你也可以发挥想象力,挖掘大模型的无限潜力。
3.2 通义大模型介绍
3.2.1 通义千问
你可以直接访问通义官网或百炼平台来体验通义千问大模型。通义千问是阿里巴巴超大规模语言模型,能帮你写文案、代码,解答问题,提升工作效率,满足个性化创作需求,甚至还能与你进行趣味互动。
千岛湖地区今天的天气怎么样?(查询天气情况需要访问模型体验,在模型配置中开启搜索能力)

在回答用户问题时,通义官网的大模型会根据实际需要自动搜索相关领域的知识来帮助生成答案。
分析图中信息,并制作表格(图表解读需要使用通义千问VL模型,先上传图片后提问)
3.3 通义模型应用介绍
3.3.1通义灵码
如果你在代码开发中遇到了问题,可以在代码编辑器中安装通义灵码插件,它可以帮助你进行代码优化、代码生成、代码解释、单元测试生成等功能。

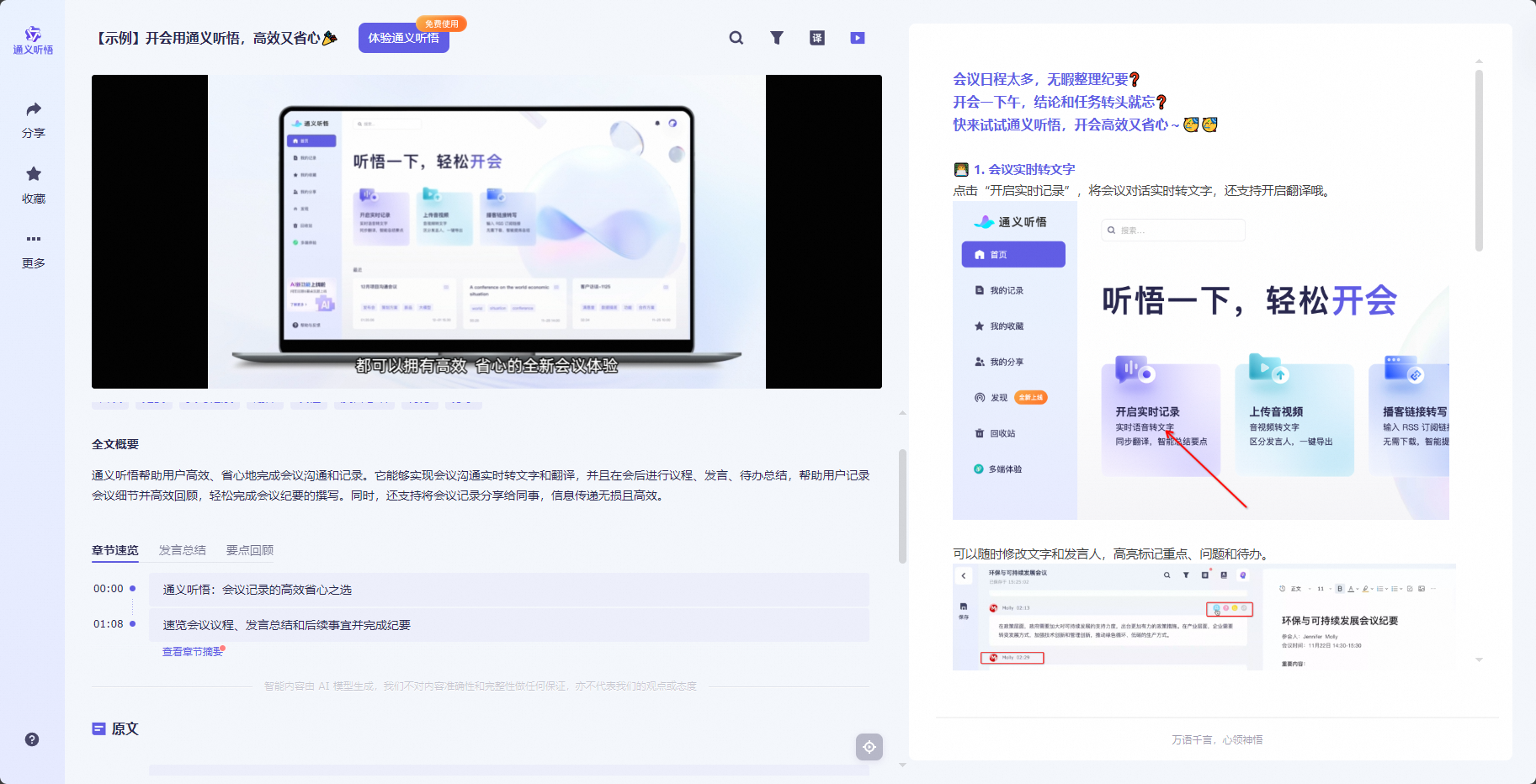
3.3.2 通义听悟
如果你在参与线上会议时需要一个听写速记员,或者你需要一个同声传译的翻译员,你可以考虑使用通义听悟。这是一款基于通义千问大模型的智能语音转文字和内容分析工具,可以实现会议记录、采访录音整理、学习笔记生成、视频字幕添加等功能。
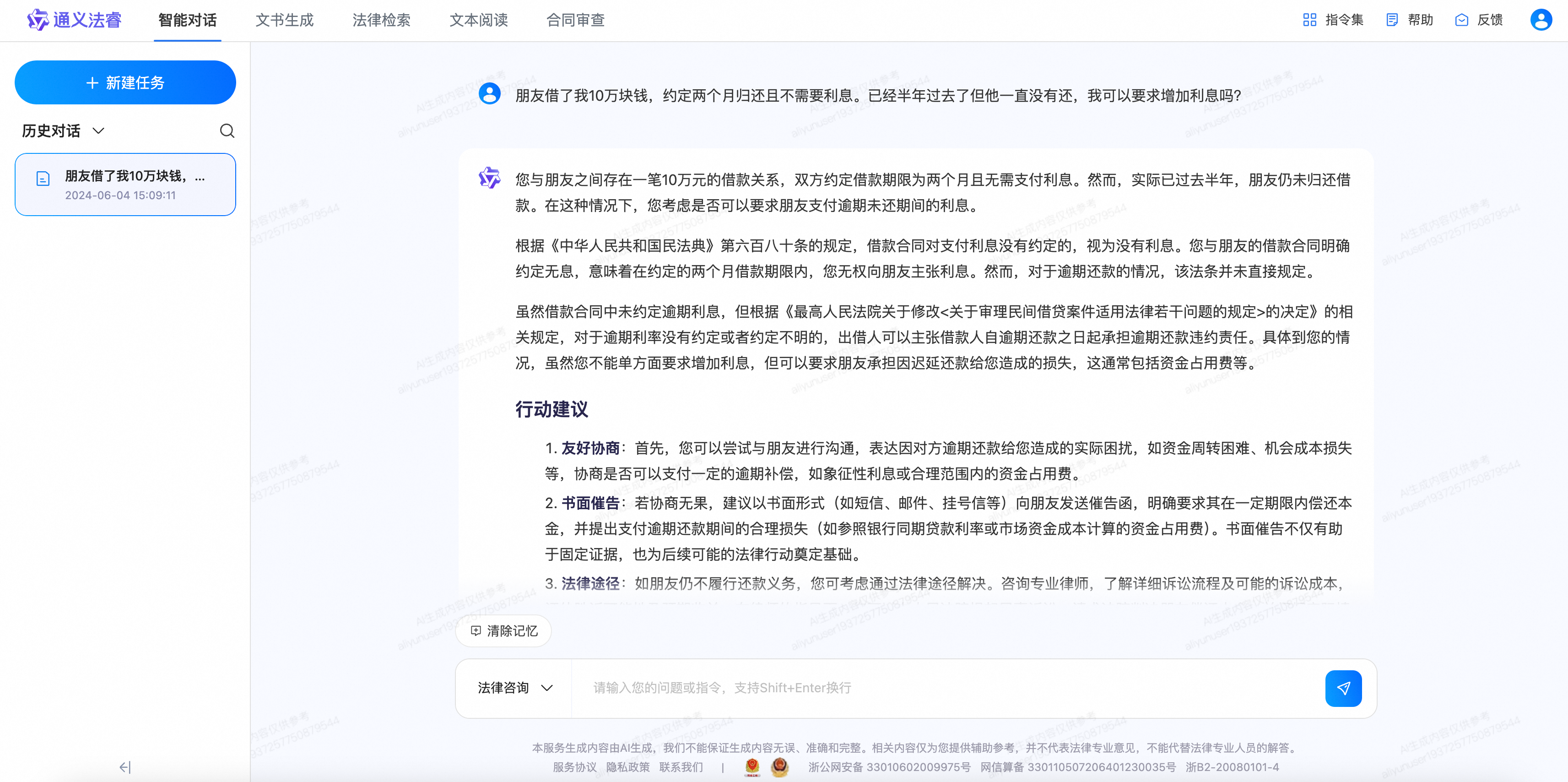
3.3.3 通义法睿
如果你有法律方面的需求,无论是合同审核、法律咨询还是文书起草等,都可以使用通义法睿。这款产品融合了先进的AI技术和丰富的法律知识,能解答法律问题、审查合同、定位法律信息、撰写法律文书、分析案情,为用户提供专业、高效、便捷的法律服务。
3.3.4 通义晓蜜
如果你的企业有庞大的客户咨询需求,可以考虑使用通义晓蜜来节省人力成本。它是一款基于大模型技术的智能对话解决方案,可以帮助企业实现客户服务的智能化升级。它不仅能够提供7*24小时不间断的服务支持,还具备强大的多轮对话、文档问答等能力,适用于多种业务场景。
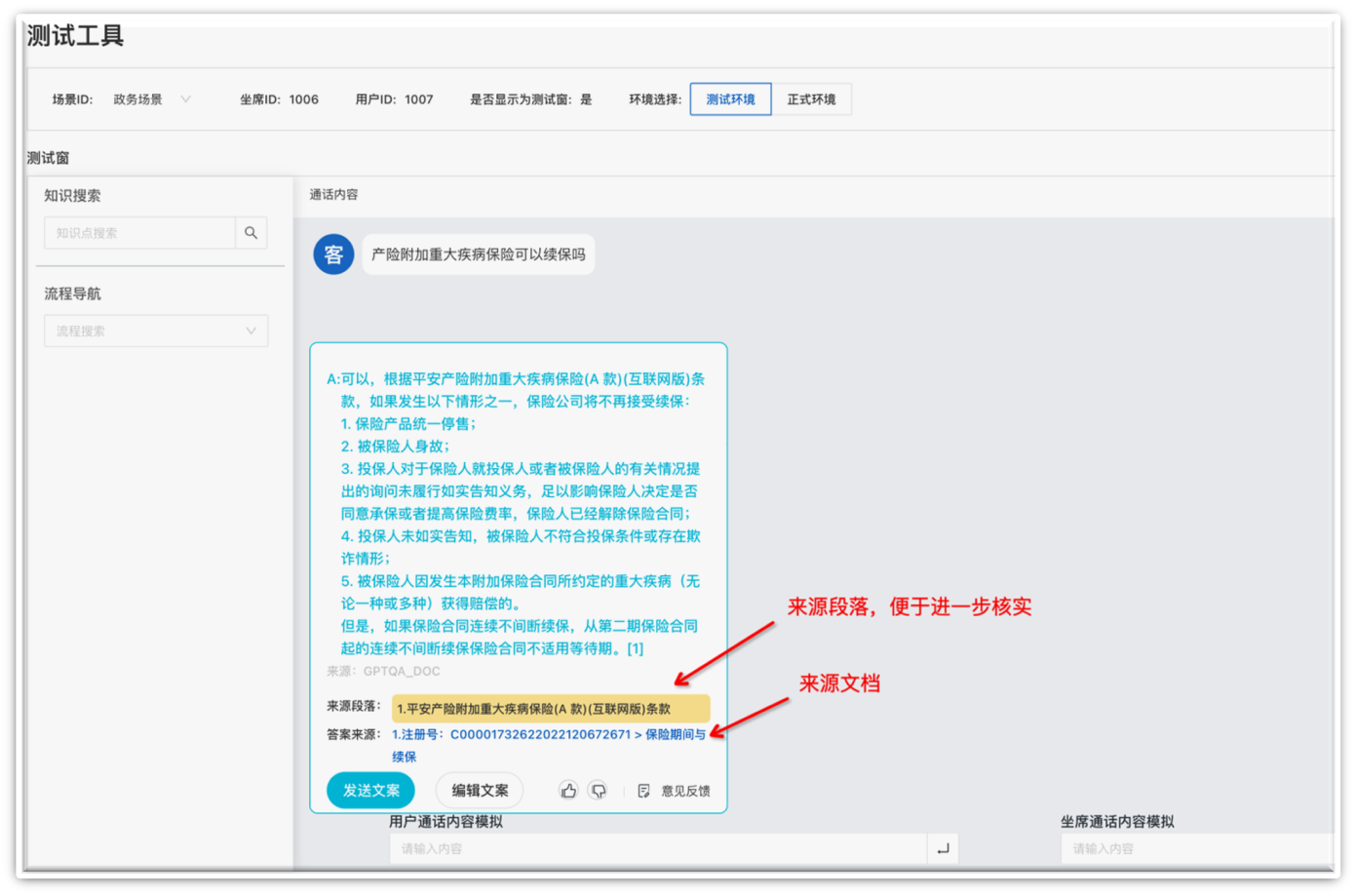
自动为坐席人员推荐基于事实的准确答案,精确到出处段落。
通义模型应用还包括:AI阅读助手通义效率、个人智能金融助手通义点金、角色对话智能体通义星尘。你可以通过体验通义系列产品,了解大模型技术对个人和企业带来的无限可能!
课后小测验
【多选题】以下描述正确的选项是()
- 大模型生成文本没有中间过程,是一步到位的
- 多模态大模型可以处理文本、图像等格式的数据
- 优秀的基础模型(大模型)只需要自身庞大的参数规模和计算硬件,对训练数据量没有太大要求
- 小明希望做一个企业专有的知识库工程,他可以在基座模型上用微调的形式来实现
正确答案:B,D
下面是对问题的回答以及每个选项的解释:
【多选题】以下描述正确的选项是(B,D)
A. 大模型生成文本没有中间过程,是一步到位的
- 错误。大模型会在每一步生成一个词或一个子词,然后利用当前生成的文本作为下一步生成的输入,逐步生成更长的文本。因此,并不是一步到位的。
B. 多模态大模型可以处理文本、图像等格式的数据
- 正确。多模态大模型具备处理多种类型数据的能力,包括但不限于文本、图像、音频、视频和其他数据格式等。
C. 优秀的基础模型(大模型)只需要自身庞大的参数规模和计算硬件,对训练数据量没有太大要求
- 错误。如果训练数据量不足或质量不高,即便增大模型参数或提升计算资源,也难以取得好的效果。
D. 小明希望做一个企业专有的知识库工程,他可以在基座模型上用微调的形式来实现
- 正确。微调(fine-tuning)是一种常见的方法,可以在一个已经预训练的基础模型(如GPT-3、BERT等)上,通过使用特定领域的数据进行进一步训练,从而定制模型以满足特定应用需求。通过微调,小明可以将预训练的大模型调整为适合企业专有知识库的模型。
继续学习
通过前面的学习,我们了解了大模型的一些重要概念、大模型是如何工作的,以及大模型的部分应用场景。
使用大模型并不复杂,但是用好大模型却有很多值得学习的技巧和技术。
- 开始使用:首先遇到任何问题时你都应该想到大模型,尝试思考该问题是否能借助大模型来解决。
-
不断改进:
- 如果大模型能解决你的问题,但是生成内容质量上还有待提升,你可以尝试改进提问方式(提示词)。
- 如果在你的业务场景中,大模型总是在编造一些内容(幻觉),你可以考虑将检索和大模型结合起来(RAG)减少幻觉。
- 如果你需要大模型在内容生成上稳定地遵循特定风格或者格式,则可以考虑微调大模型。
当然,用好大模型的技巧和技术远不止这些,在接下来的章节里,我们将一起学习一些能帮助你用好大模型的技巧和技术。




发表评论 取消回复