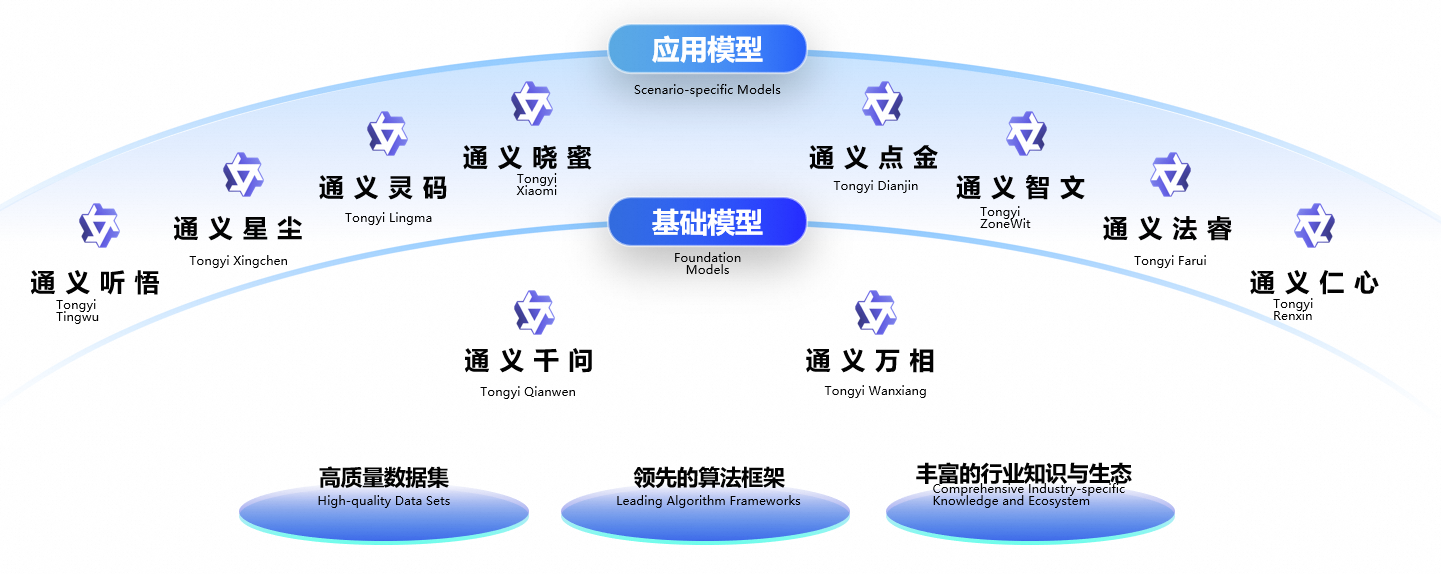
1 多模态大模型
1.1 什么是多模态大模型
而在大模型领域,模态指的是数据或信息的类型或表达形式,文本、图像、视频、音频等都是不同的模态。多模态,顾名思义,就是指结合两种及以上的模态,进行更综合的数据处理和分析。如果想要大模型真正模拟人类,实现多形式的输入和生成,单一类型的数据处理已经无法满足,大模型需具备同时处理和理解多种类型数据的能力。
在前文中,我们学习了使用ModelScope-Agent通过文字生成视频、图片或语音,这本身就是一个多模态应用。除了这种代理方式外,大模型本身也可以是多模态的,也就是多模态大模型,有同时处理多模态数据(如文本、图像、音频等)和执行复杂任务的能力,比如文生图、语音识别、图像字幕等。


1.2 体验多模态大模型
目前,市面上已经有很多商业化或开源的多模态大模型,你可以直接访问网页端使用,也可以直接调用API集成在业务中。例如:
2 混合专家模型(MoE)
2.1 什么是混合专家模型
简单来说,混合专家模型的核心思想就是术有专攻,类似“专家会诊”,由多个不同领域的模型(即“专家”)组合成一个模型,分别去解决不同领域的问题。
混合专家模型主要由以下2个核心组件共同协作:
-
Experts(专家网络):每个专家网络是用来处理某一特定类型问题或数据子集的独立模型,一般都在他们各自的专长上受过训练,推理时只有部分专家网络参与计算。
-
GateNet(门控网络):类似于“交通指挥官”,负责评估输入数据,并决定由哪些专家参与处理当前的问题,尽可能地利用每个专家的专业知识来提供最准确的预测或决策输出。

2.2 混合专家模型的局限
-
计算资源需求高:MoE模型中的每个专家都是一个独立的模型,当专家数量增加时,模型的总参数量也相应增加,导致部署模型可能需要更多的GPU显存资源。
-
过拟合风险:由于参数量大和复杂性,可能比简单模型更容易过拟合训练数据,特别是当数据量不足时。
2.3 更多了解
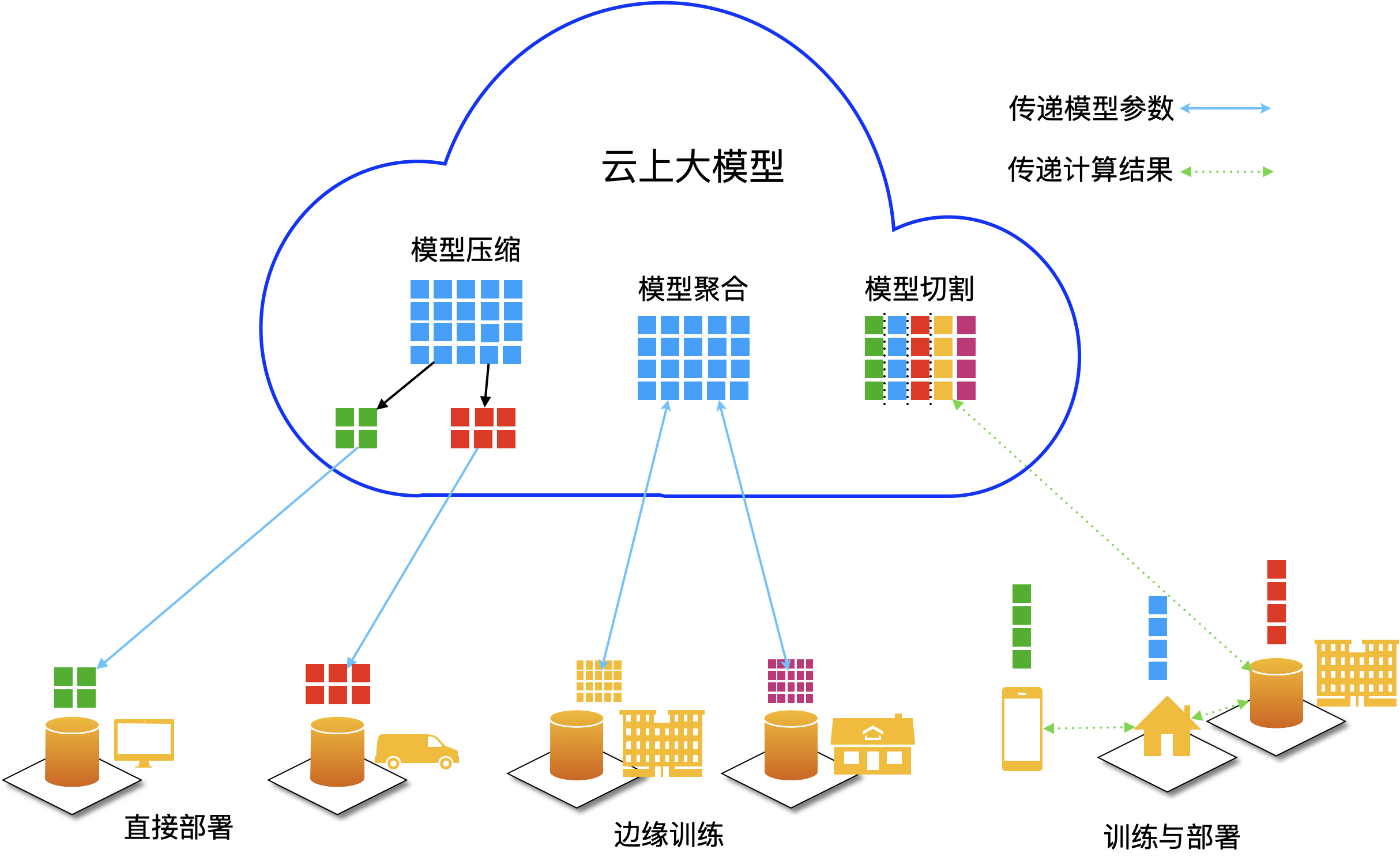
文本模型体验。3 大小模型云端协同
模型的大小通常与模型的规模、复杂度和参数数量有关,无论是大模型还是小模型,都各有优劣。
“大模型”,顾名思义,参数规模庞大且结构复杂度高,能处理复杂的任务,准确率和泛化能力强,训练和推理需要大量的计算资源和时间,不适合直接部署在资源受限的设备上(如移动设备)。
与之对应的就是“小模型”,参数规模较小、计算密度较低,在性能上可能不及大模型,但对比大模型,训练和推理的资源需求较低,响应速度更快,适合在资源受限的环境下运行,如移动设备、边缘计算设备。
然而,在实际应用中,一个系统通常需要同时考虑到性能、响应效率、数据隐私、成本和资源使用效率,单独使用大模型或小模型很难满足所有这些需求。例如,一个电商APP为亿级用户提供服务,如果仅用单一超大模型提供服务,日常每秒超过万次请求,峰值每秒超过10万次请求,如果遇到服务高峰期,一次请求的延时可能会超过一分钟,严重影响用户体验。
2022年十大科技趋势提出大小模型云端协同的概念,将大模型部署在云端,向边、端的小模型输出模型能力,小模型负责实时数据处理和初步推理,并向大模型反馈算法与执行成效,这样既能在云端充分发挥大模型的推理训练能力,又能调动边、端的小模型的敏捷性,可实现合理分配计算资源、提高响应速度。




发表评论 取消回复